
I was looking for a way to run an Elasticsearch cluster for testing purposes by emulating a multi-node production setup on a single server. Instead of setting up multiple virtual machines on my test server, I decided to use Docker. With the resource limiting options in Docker and the bridge network driver, I can build a test environment and run my tests way faster than using VMs.
Running a single instance
In order to monitor my Elasticsearch cluster I’ve created an ES image that has the HQ and KOPF plugins pre-installed along with a Docker healthcheck command that checks the cluster health status.
FROM elasticsearch:2.4.1
RUN /usr/share/elasticsearch/bin/plugin install --batch royrusso/elasticsearch-HQ
RUN /usr/share/elasticsearch/bin/plugin install --batch lmenezes/elasticsearch-kopf
COPY docker-healthcheck /usr/local/bin/
RUN chmod +x /usr/local/bin/docker-healthcheck
HEALTHCHECK CMD ["docker-healthcheck"]
I’ve built my image and created a bridge network for the ES cluster:
docker build -t es-t .
docker network create es-net
Next I’ve started an Elasticseach node with the following command:
docker run -d -p 9200:9200 \
--name es-t0 \
--network es-net \
-v "$PWD/storage":/usr/share/elasticsearch/data \
--cap-add=IPC_LOCK --ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
--memory="2g" --memory-swap="2g" --memory-swappiness=0 \
-e ES_HEAP_SIZE="1g" \
es-t \
-Des.bootstrap.mlockall=true \
-Des.network.host=_eth0_ \
-Des.discovery.zen.ping.multicast.enabled=false
With --memory="2g" and -e ES_HEAP_SIZE="1g" I limit the container memory to 2GB and the ES heap size to 1GB.
Prevent Elasticsearch from swapping
In order to instruct the ES node not to swap its memory you need to enable memory and swap accounting on your system.
On Ubuntu you have to edit /etc/default/grub file and add this line:
GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"
Then run sudo update-grub and reboot the server.
Now that your server supports swap limit capabilities you can use --memory-swappiness=0 and set --memory-swap equal to --memory.
You also need to set -Des.bootstrap.mlockall=true.
Running a two node cluster
For a second node to join the cluster I need to tell it how to find the first node. By starting the second node on the es-net network I can use the other node’s host name instead of its IP to point the second node to its master.
docker run -d -p 9201:9200 \
--name es-t1 \
--network es-net \
-v "$PWD/storage":/usr/share/elasticsearch/data \
--cap-add=IPC_LOCK --ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
--memory="2g" --memory-swap="2g" --memory-swappiness=0 \
-e ES_HEAP_SIZE="1g" \
es-t \
-Des.bootstrap.mlockall=true \
-Des.network.host=_eth0_ \
-Des.discovery.zen.ping.multicast.enabled=false \
-Des.discovery.zen.ping.unicast.hosts="es-t0"
Since the first node is using the 9200 port I need to map different port for the second node to be accessible from outside. Note that I’m not exposing the transport port 7300 on the host. This port is accessible only from the es-net network.
With -Des.discovery.zen.ping.unicast.hosts="es-t0" I point es-t1 to es-t0 address.
The problem with this approach is that the es-t0 node doesn’t know the address of es-t1 so I need to recreate es-t0 with -Des.discovery.zen.ping.unicast.hosts="es-t1:9301".
Running multiple nodes in this manner seems like a daunting task.
Provisioning and running a multi-node cluster
To speed things up, I’ve made a script that automates the cluster provisioning. The script asks for the cluster size, storage location and memory limit. With these informations it can compose the discovery hosts location and point each node to the rest of the cluster nodes.
#!/bin/bash
set -e
read -p "Enter cluster size: " cluster_size
read -p "Enter storage path: " storage
read -p "Enter node memory (mb): " memory
heap=$((memory/2))
image="es-t"
network="es-net"
cluster="cluster-t"
# build image
if [ ! "$(docker images -q $image)" ];then
docker build -t $image .
fi
# create bridge network
if [ ! "$(docker network ls --filter name=$network -q)" ];then
docker network create $network
fi
# concat all nodes addresses
hosts=""
for ((i=0; i<$cluster_size; i++)); do
hosts+="$image$i"
[ $i != $(($cluster_size-1)) ] && hosts+=","
done
# starting nodes
for ((i=0; i<$cluster_size; i++)); do
echo "Starting node $i"
docker run -d -p 920$i:9200 \
--name "$image$i" \
--network "$network" \
-v "$storage":/usr/share/elasticsearch/data \
-v "$PWD/config/elasticsearch.yml":/usr/share/elasticsearch/config/elasticsearch.yml \
--cap-add=IPC_LOCK --ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
--memory="${memory}m" --memory-swap="${memory}m" --memory-swappiness=0 \
-e ES_HEAP_SIZE="${heap}m" \
-e ES_JAVA_OPTS="-Dmapper.allow_dots_in_name=true" \
--restart unless-stopped \
$image \
-Des.node.name="$image$i" \
-Des.cluster.name="$cluster" \
-Des.network.host=_eth0_ \
-Des.discovery.zen.ping.multicast.enabled=false \
-Des.discovery.zen.ping.unicast.hosts="$hosts" \
-Des.cluster.routing.allocation.awareness.attributes=disk_type \
-Des.node.rack=dc1-r1 \
-Des.node.disk_type=spinning \
-Des.node.data=true \
-Des.bootstrap.mlockall=true \
-Des.threadpool.bulk.queue_size=500
done
echo "waiting 15s for cluster to form"
sleep 15
# find host IP
host="$(ifconfig eth0 | sed -En 's/.*inet (addr:)?(([0-9]*\.){3}[0-9]*).*/\2/p')"
# get cluster status
status="$(curl -fsSL "http://${host}:9200/_cat/health?h=status")"
echo "cluster health status is $status"
You should change -Des.node.disk_type=spinning to -Des.node.disk_type=ssd if your storage runs on SSD drives. Also you should adjust Des.threadpool.bulk.queue_size to your needs.
The above script along with the Dockerfile and the Elasticsearch config file are available on GitHub at stefanprodan/dockes.
Clone the repository on your Docker host, cd into dockes directory and run sh.up:
$ bash sh.up
Enter cluster size: 3
Enter storage path: /storage
Enter node memory (mb): 1024
Output:
Successfully built b9f33d9910e1
Starting node 0
c0c7ac1e9b284b2f90ff0f2b621a8a0ea3a79096ddff88178544da1741a72c3a
Starting node 1
318bbda182684c624eee55b87b91a614843276f70ad43221873827485aef506a
Starting node 2
318bbda182684c624eee55b87b91a614843276f70ad43221873827485aef506a
waiting 15s for the cluster to form
cluster health status is green
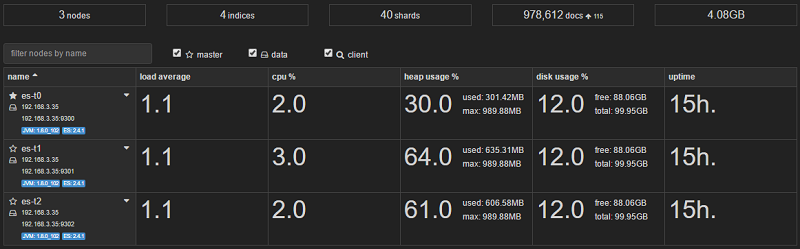
You can now access HQ or KOPF to check your cluster status.
http://<HOST-IP>:9200/_plugin/hq/#cluster
http://<HOST-IP>:9200/_plugin/kopf/#!/cluster
I’ve made a teardown script so you can easily remove the cluster and the ES image:
#!/bin/bash
read -p "Enter cluster size: " cluster_size
image="es-t"
# stop and remove containers
for ((i=0; i<$cluster_size; i++)); do
docker rm -f "$image$i"
done
# remove image
docker rmi -f "$image"
Run teardown:
$ bash down.up
Enter cluster size: 3
Output:
es-t0
es-t1
es-t2
Untagged: es-t:latest
Deleted: sha256:....
If you have any suggestion on improving dockes please submit an issue or PR on GitHub. Contributions are more than welcome!